This article will go through my implementation/design of a large scale autocomplete/typeahead suggestions system design, like the suggestions one gets when typing a Google search.
This design was implemented using Docker Compose1, and you can find the source code here: https://github.com/lopespm/autocomplete
YouTube video overview of this implementation
Requirements
The design has to accommodate a Google-like scale of about 5 billion daily searches, which translates to about 58 thousand queries per second. We can expect 20% of these searches to be unique, this is, 1 billion queries per day.
If we choose to index 1 billion queries, with 15 characters on average per query2 and 2 bytes per character (we will only support the english locale), then we will need about 30GB of storage to host these queries.
Functional Requirements
- Get a list of top phrase suggestions based on the user input (a prefix)
- Suggestions ordered by weighting the frequency and recency of a given phrase/query3
The main two APIs will be:
- top-phrases(prefix): returns the list of top phrases for a given prefix
- collect-phrase(phrase): submits the searched phrase to the system. This phrase will later be used by the assembler to build a data structure which maps a prefix to a list of top phrases
Non-Functional Requirements
- Highly Available
- Performant - response time for the top phrases should be quicker than the user’s type speed (< 200ms)
- Scalable - the system should accommodate a large number of requests, while still maintaining its performance
- Durable - previously searched phrases (for a given timespan) should be available, even if there is a hardware fault or crash
Design & Implementation
High-level Design
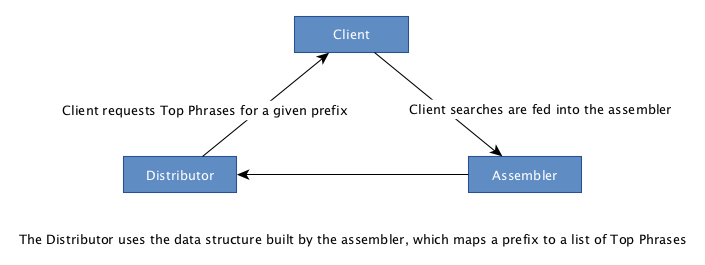
The two main sub-systems are:
- the distributor, which handles the user’s requests for the top phrases of a given prefix
- the assembler, which collects user searches and assembles them into a data structure that will later be used by the distributor
Detailed Design
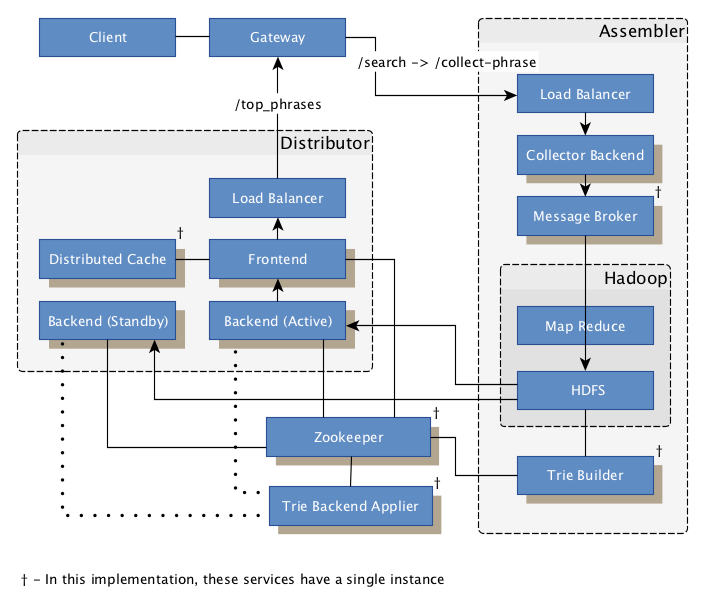
This implementation uses off-the-shelf components like kafka (message broker), hadoop (map reduce and distributed file system), redis (distributed cache) and nginx (load balancing, gateway, reverse proxy), but also has custom services built in python, namely the trie distribution and building services. The trie data structure is custom made as well.
The backend services in this implementation are built to be self sustainable and don’t require much orchestration. For example, if an active backend host stops responding, it’s corresponding ephemeral znode registry eventually disappears, and another standby backend node takes its place by attempting to claim the position via an ephemeral sequential znode on zookeeper.
Trie: the bedrock data structure
The data structure used by, and provided to the distributor is a trie, with each of its prefix nodes having a list of top phrases. The top phrases are referenced using the flyweight pattern, meaning that the string literal of a phrase is stored only once. Each prefix node has a list of top phrases, which are a list of references to string literals.
As we’ve seen before, we will need about 30GB to index 1 billion queries, which is about the memory we would need for the above mentioned trie to store 1 billion queries. Since we want to keep the trie in memory to enable fast lookup times for a given query, we are going to partition the trie into multiple tries, each one on a different machine. This relieves the memory load on any given machine.
For increased availability, the services hosting these tries will also have multiple replicas. For increased durability, the serialized version of the tries will be available in a distributed file system (HDFS), and these can be rebuilt via map reduce tasks in a predictable, deterministic way.
Information Flow
Assembler: collect data and assemble the tries
- Client submits the searched phrase to the gateway via
http://localhost:80/search?phrase="a user query" - Since the search service is outside the scope of this implementation, the gateway directly sends the searched phrase to the collector’s load balancer via
http://assembler.collector-load-balancer:6000/collect-phrase?phrase="a user query" - The collector’s load balancer forwards the request to one of the collector backends via
http://assembler.collector:7000/collect-phrase?phrase="a user query" - The collector backend sends a message to the phrases topic to the message broker (kafka). The key and value are the phrase itself 4
- The Kafka Connect HDFS Connector
assembler.kafka-connectdumps the messages from the phrases topic into the/phrases/1_sink/phrases/{30 minute window timestamp}5 folder 6 - Map Reduce jobs are triggered 7: they will reduce the searched phrases into a single HDFS file, by weighting the recency and frequency of each phrase 8
- A
TARGET_IDis generated, according to the current time, for exampleTARGET_ID=20200807_1517 - The first map reduce job is executed for the K 9 most recent
/phrases/1_sink/phrases/{30 minute window timestamp}folders, and attributes a base weight for each of these (the more recent, the higher the base weight). This job will also sum up the weights for the same phrase in a given folder. The resulting files will be stored in the/phrases/2_with_weight/2_with_weight/{TARGET_ID}HDFS folder - The second map reduce job will sum up all the weights of a given phrase from
/phrases/2_with_weight/2_with_weight/{TARGET_ID}into/phrases/3_with_weight_merged/{TARGET_ID} - The third map reduce job will order the entries by descending weight, and pass them through a single reducer, in order to produce a single file. This file is placed in
/phrases/4_with_weight_ordered/{TARGET_ID} - The zookeper znode
/phrases/assembler/last_built_targetis set to theTARGET_ID
- A
- The Trie Builder service, which was listening to changes in the
/phrases/assembler/last_built_targetznode, builds a trie for each partition10, based on the/phrases/4_with_weight_ordered/{TARGET_ID}file. For example, one trie may cover the prefixes until mod, another from mod to racke, and another from racke onwards.- Each trie is serialized and written into the
/phrases/5_tries/{TARGET_ID}/{PARTITION}HDFS file (e.g./phrases/5_tries/20200807_1517/mod\|racke), and the zookeeper znode/phrases/distributor/{TARGET_ID}/partitions/{PARTITION}/trie_data_hdfs_pathis set to the previously mentioned HDFS file path. - The service sets the zookeper znode
/phrases/distributor/next_targetto theTARGET_ID
- Each trie is serialized and written into the
Transfering the tries to the Distributor sub-system
- The distributor backend nodes can either be in active mode (serving requests) or standby mode. The nodes in standby mode will fetch the most recent tries, load them into memory, and mark themselves as ready to take over the active position. In detail:
- The standby nodes, while listening to changes to the znode
/phrases/distributor/next_target, detect its modification and create an ephemeral sequential znode, for each partition, one at a time, inside the/phrases/distributor/{TARGET_ID}/partitions/{PARTITION}/nodes/znode. If the created znode is one of the first R znodes (R being the number of replica nodes per partition 11), proceed to the next step. Otherwise, remove the znode from this partition and try to join the next partition. - The standby backend node fetches the serialized trie file from
/phrases/5_tries/{TARGET_ID}/{PARTITION}, and starts loading the trie into memory. - When the trie is loaded into memory, the standby backend node marks itself as ready by setting the
/phrases/distributor/{TARGET_ID}/partitions/{PARTITION}/nodes/{CREATED_ZNODE}znode to the backend’s hostname.
- The standby nodes, while listening to changes to the znode
- The Trie Backend Applier service polls the
/phrases/distributor/{TARGET_ID}/sub-znodes (theTARGET_IDis the one defined in/phrases/distributor/next_target), and checks if all the nodes in all partitions are marked as ready- If all of them are ready for this next
TARGET_ID, the service, in a single transaction, changes the value of the/phrases/distributor/next_targetznode to empty, and sets the/phrases/distributor/current_targetznode to the newTARGET_ID. With this single step, all of the standby backend nodes which were marked as ready will now be active, and will be used for the following Distributor requests.
- If all of them are ready for this next
Distributor: handling the requests for Top Phrases
With the distributor’s backend nodes active and loaded with their respective tries, we can start serving top phrases requests for a given prefix:
- Client requests the gateway for the top phrases for a given prefix via
http://localhost:80/top-phrases?prefix="some prefix" - The gateway sends this request to the distributor’s load balancer via
http://distributor.load-balancer:5000/top-phrases?prefix="some prefix" - The load balancer forwards the request to one of the frontends via
http://distributor.frontend:8000/top-phrases?prefix="some prefix" - The frontend service handles the request:
- The frontend service checks if the distributed cache (redis) has an entry for this prefix 12. If it does, return these cached top phrases. Otherwise, continue to next step
- The frontend service gets the partitions for the current
TARGET_IDfrom zookeeper (/phrases/distributor/{TARGET_ID}/partitions/znode), and picks the one that matches the provided prefix - The frontend service chooses a random znode from the
/phrases/distributor/{TARGET_ID}/partitions/{PARTITION}/nodes/znode, and gets its hostname - The frontend service requests the top phrases, for the given prefix, from the selected backend via
http://{BACKEND_HOSTNAME}:8001/top-phrases="some prefix"- The backend returns the list of top phrases for the given prefix, using its corresponding loaded trie
- The frontend service inserts the list of top phrases into the distributed cache (cache aside pattern), and returns the top phrases
- The top phrases response bubbles up to the client
Zookeper Znodes structure
Note: Execute the shell command docker exec -it zookeeper ./bin/zkCli.sh while the system is running to explore the current zookeeper’s znodes.
- phrases
- distributor
- assembler
- last_built_target - set to a
TARGET_ID
- last_built_target - set to a
- distributor
- current_target - set to a
TARGET_ID - next_target - set to a
TARGET_ID {TARGET_ID}- e.g. 20200728_2241- partitions
- |{partition 1 end}
- trie_data_hdfs_path - HDFS path where the serialized trie is saved
- nodes
- 0000000000
- 0000000001
- 0000000002
- …
- {partition 2 start}|{partition 2 end}
- …
- {partition 3 start}|
- …
- |{partition 1 end}
- partitions
- current_target - set to a
HDFS folder structure
Note: Access http://localhost:9870/explorer.html in your browse while the system is running to browse the current HDFS files and folders.
- phrases
- 1_sink *- the searched phrases are dumped here, partitioned into 30min time blocks, *
- {e.g 20200728_2230}
- {e.g 20200728_2300}
- 2_with_weight - phrases with their initial weight applied, divided by time block
{TARGET_ID}
- 3_with_weight_merged - consolidation of all the time blocks: phrases with their final weight
{TARGET_ID}
- 4_with_weight_ordered - single file of phrases ordered by descending weight
{TARGET_ID}
- 5_tries - storage of serialized tries
{TARGET_ID}- |{partition 1 end}
- {partition 2 start}|{partition 2 end}
- {partition 3 start}|
- 1_sink *- the searched phrases are dumped here, partitioned into 30min time blocks, *
Client interaction
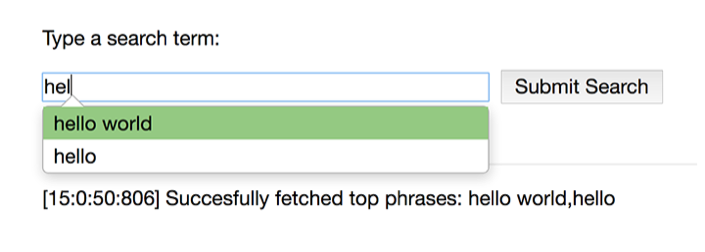
You can interact with the system by accessing http://localhost in your browser. The search suggestions will be provided by the system as you write a query, and you can feed more queries/phrases into the system by submitting more searches.
Source Code
You can get the full source code at https://github.com/lopespm/autocomplete. I would be happy to know your thoughts about this implementation and design.
-
Docker compose was used instead of a container orchestrator tool like Kubernetes or Docker Swarm, since the main objective of this implementation was to build and share a system in simple manner.↩
-
The average length of a search query was 2.4 terms, and the average word length in English language is 4.7 characters↩
-
Phrase and Query are used interchangeably in this article. Inside the system though, only the term Phrase is used.↩
-
In this implementation, only one instance of the broker is used, for clarity. However, for a large number of incoming requests it would be best to partition this topic along multiple instances (the messages would be partitioned according to the phrase key), in order to distribute the load.↩
-
/phrases/1_sink/phrases/{30 minute window timestamp} folder: For example, provided the messages A[time: 19h02m], B[time: 19h25m], C[time: 19h40m], the messages A and B would be placed into folder /phrases/1_sink/phrases/20200807_1900, and message C into folder /phrases/1_sink/phrases/20200807_1930↩
-
We could additionally pre-aggregate these messages into another topic (using Kafka Streams), before handing them to Hadoop↩
-
For clarity, the map reduce tasks are triggered manually in this implementation via make do_mapreduce_tasks, but in a production setting they could be triggered via cron job every 30 minutes for example.↩
-
An additional map reduce could be added to aggregate the /phrases/1_sink/phrases/ folders into larger timespan aggregations (e.g. 1-day, 5-week, 10-day, etc)↩
-
Configurable in assembler/hadoop/mapreduce-tasks/do_tasks.sh, by the variable MAX_NUMBER_OF_INPUT_FOLDERS↩
-
Partitions are defined in assembler/trie-builder/triebuilder.py↩
-
The number of replica nodes per partition is configured via the environment variable NUMBER_NODES_PER_PARTITION in docker-compose.yml↩
-
The distributed cache is disabled by default in this implementation, so that it is clearer for someone using this codebase for the first time to understand what is happening on each update/step. The distributed cache can be enabled via the environment variable DISTRIBUTED_CACHE_ENABLED in docker-compose.yml↩